Netty分布式解码器读取数据不完整的逻辑剖析
概述
在我们上一个章节遗留过一个问题, 就是如果server在读取客户端的数据的时候, 如果一次读取不完整, 就触发channelread事件, 那么netty是如何处理这类问题的, 在这一章中, 会对此做详细剖析
之前的章节我们学习过pipeline, 事件在pipeline中传递, handler可以将事件截取并对其处理, 而之后剖析的编解码器, 其实就是一个handler, 截取bytebuf中的字节, 然后组建成业务需要的数据进行继续传播
编码器, 通常是outboundhandler, 也就是以自身为基准, 对那些对外流出的数据做处理, 所以也叫编码器, 将数据经过编码发送出去
解码器, 通常是inboundhandler, 也就是以自身为基准, 对那些流向自身的数据做处理, 所以也叫解码器, 将对向的数据接收之后经过解码再进行使用
同样, 在netty的编码器中, 也会对半包和粘包问题做相应的处理
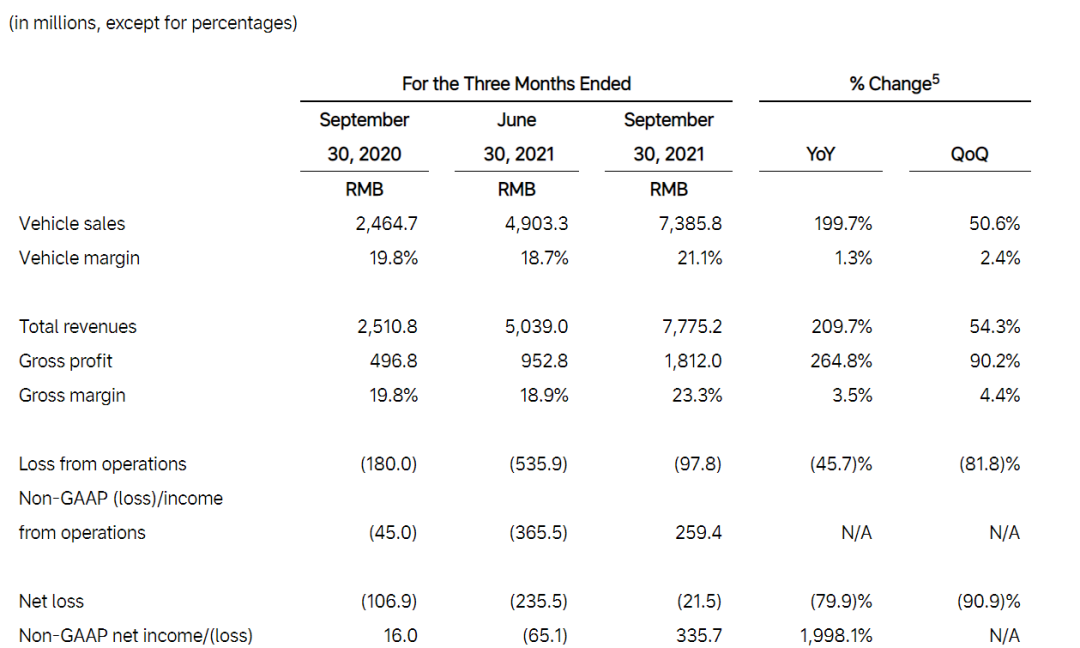
什么是半包, 顾名思义, 就是不完整的数据包, 因为netty在轮询读事件的时候, 每次将channel中读取的数据, 不一定是一个完整的数据包, 这种情况, 就叫半包
粘包同样也不难理解, 如果client往server发送数据包, 如果发送频繁很有可能会将多个数据包的数据都发送到通道中, 如果在server在读取的时候可能会读取到超过一个完整数据包的长度, 这种情况叫粘包
有关半包和粘包, 入下图所示:

6-0-1
netty对半包的或者粘包的处理其实也很简单, 通过之前的学习, 我们知道, 每个handler是和channel唯一绑定的, 一个handler只对应一个channel, 所以将channel中的数据读取时候经过解析, 如果不是一个完整的数据包, 则解析失败, 将这块数据包进行保存, 等下次解析时再和这个数据包进行组装解析, 直到解析到完整的数据包, 才会将数据包进行向下传递
具体流程是在代码中如何体现的呢?我们进入到源码分析中
第一节: bytetomessagedecoder
bytetomessagedecoder解码器, 顾名思义, 是一个将byte解析成消息的解码器,
我们看他的定义
public abstract class bytetomessagedecoder extends channelinboundhandleradapter{
//类体省略
}这里继承了channelinboundhandleradapter, 根据之前的学习, 我们知道, 这是个inbound类型的handler, 也就是处理流向自身事件的handler
其次, 该类通过abstract关键字修饰, 说明是个抽象类, 在我们实际使用的时候, 并不是直接使用这个类, 而是使用其子类, 类定义了解码器的骨架方法, 具体实现逻辑交给子类, 同样, 在半包处理中也是由该类进行实现的
netty中很多解码器都实现了这个类, 并且, 我们也可以通过实现该类进行自定义解码器
我们重点关注一下该类的一个属性:
bytebuf cumulation;
这个属性, 就是有关半包处理的关键属性, 从概述中我们知道, netty会将不完整的数据包进行保存, 这个数据包就是保存在这个属性中
之前的学习我们知道, bytebuf读取完数据会传递channelread事件, 传播过程中会调用handler的channelread方法, bytetomessagedecoder的channelread方法, 就是编码的关键部分
我们看其channelread方法
public void channelread(channelhandlercontext ctx, object msg) throws exception {
//如果message是bytebuf类型
if (msg instanceof bytebuf) {
//简单当成一个arraylist, 用于盛放解析到的对象
codecoutputlist out = codecoutputlist.newinstance();
try {
bytebuf data = (bytebuf) msg;
//当前累加器为空, 说明这是第一次从io流里面读取数据
first = cumulation == null;
if (first) {
//如果是第一次, 则将累加器赋值为刚读进来的对象
cumulation = data;
} else {
//如果不是第一次, 则把当前累加的数据和读进来的数据进行累加
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
//调用子类的方法进行解析
calldecode(ctx, cumulation, out);
} catch (decoderexception e) {
throw e;
} catch (throwable t) {
throw new decoderexception(t);
} finally {
if (cumulation != null && !cumulation.isreadable()) {
numreads = 0;
cumulation.release();
cumulation = null;
} else if (++ numreads >= discardafterreads) {
numreads = 0;
discardsomereadbytes();
}
//记录list长度
int size = out.size();
decodewasnull = !out.insertsincerecycled();
//向下传播
firechannelread(ctx, out, size);
out.recycle();
}
} else {
//不是bytebuf类型则向下传播
ctx.firechannelread(msg);
}
}这方法比较长, 带大家一步步剖析
首先判断如果传来的数据是bytebuf, 则进入if块中
codecoutputlist out = codecoutputlist.newinstance() 这里就当成一个arraylist就好, 用于盛放解码完成的数据
bytebuf data = (bytebuf) msg 这步将数据转化成bytebuf
first = cumulation == null 这里表示如果cumulation == null, 说明没有存储板半包数据, 则将当前的数据保存在属性cumulation中
如果 cumulation != null , 说明存储了半包数据, 则通过cumulator.cumulate(ctx.alloc(), cumulation, data)将读取到的数据和原来的数据进行累加, 保存在属性cumulation中
我们看cumulator属性
private cumulator cumulator = merge_cumulator;
这里调用了其静态属性merge_cumulator, 我们跟过去:
public static final cumulator merge_cumulator = new cumulator() {
@override
public bytebuf cumulate(bytebufallocator alloc, bytebuf cumulation, bytebuf in) {
bytebuf buffer;
//不能到过最大内存
if (cumulation.writerindex() > cumulation.maxcapacity() - in.readablebytes()
|| cumulation.refcnt() > 1) {
buffer = expandcumulation(alloc, cumulation, in.readablebytes());
} else {
buffer = cumulation;
}
//将当前数据buffer
buffer.writebytes(in);
in.release();
return buffer;
}
};这里创建了cumulator类型的静态对象, 并重写了cumulate方法, 这里cumulate方法, 就是用于将bytebuf进行拼接的方法:
方法中, 首先判断cumulation的写指针+in的可读字节数是否超过了cumulation的最大长度, 如果超过了, 将对cumulation进行扩容, 如果没超过, 则将其赋值到局部变量buffer中
然后将in的数据写到buffer中, 将in进行释放, 返回写入数据后的bytebuf
回到channelread方法中:
最后通过calldecode(ctx, cumulation, out)方法进行解码, 这里传入了context对象, 缓冲区cumulation和集合out:
我们跟到calldecode(ctx, cumulation, out)方法中:
protected void calldecode(channelhandlercontext ctx, bytebuf in, list<object> out) {
try {
//只要累加器里面有数据
while (in.isreadable()) {
int outsize = out.size();
//判断当前list是否有对象
if (outsize > 0) {
//如果有对象, 则向下传播事件
firechannelread(ctx, out, outsize);
//清空当前list
out.clear();
//解码过程中如ctx被removed掉就break
if (ctx.isremoved()) {
break;
}
outsize = 0;
}
//当前可读数据长度
int oldinputlength = in.readablebytes();
//子类实现
//子类解析, 解析玩对象放到out里面
decode(ctx, in, out);
if (ctx.isremoved()) {
break;
}
//list解析前大小 和解析后长度一样(什么没有解析出来)
if (outsize == out.size()) {
//原来可读的长度==解析后可读长度
//说明没有读取数据(当前累加的数据并没有拼成一个完整的数据包)
if (oldinputlength == in.readablebytes()) {
//跳出循环(下次在读取数据才能进行后续的解析)
break;
} else {
//没有解析到数据, 但是进行读取了
continue;
}
}
//out里面有数据, 但是没有从累加器读取数据
if (oldinputlength == in.readablebytes()) {
throw new decoderexception(
stringutil.simpleclassname(getclass()) +
".decode() did not read anything but decoded a message.");
}
if (issingledecode()) {
break;
}
}
} catch (decoderexception e) {
throw e;
} catch (throwable cause) {
throw new decoderexception(cause);
}
}这里首先循环判断传入的bytebuf是否有可读字节, 如果还有可读字节说明没有解码完成, 则循环继续解码
然后判断集合out的大小, 如果大小大于1, 说明out中盛放了解码完成之后的数据, 然后将事件向下传播, 并清空out
因为我们第一次解码out是空的, 所以这里不会进入if块, 这部分我们稍后分析, 这里继续往下看
通过 int oldinputlength = in.readablebytes() 获取当前bytebuf, 其实也就是属性cumulation的可读字节数, 这里就是一个备份用于比较, 我们继续往下看:
decode(ctx, in, out)方法是最终的解码操作, 这部会读取cumulation并且将解码后的数据放入到集合out中, 在bytetomessagedecoder中的该方法是一个抽象方法, 让子类进行实现, 我们使用的netty很多的解码都是继承了bytetomessagedecoder并实现了decode方法从而完成了解码操作, 同样我们也可以遵循相应的规则进行自定义解码器, 在之后的小节中会讲解netty定义的解码器, 并剖析相关的实现细节, 这里我们继续往下看:
if (outsize == out.size()) 这个判断表示解析之前的out大小和解析之后out大小进行比较, 如果相同, 说明并没有解析出数据, 我们进入到if块中:
if (oldinputlength == in.readablebytes()) 表示cumulation的可读字节数在解析之前和解析之后是相同的, 说明解码方法中并没有解析数据, 也就是当前的数据并不是一个完整的数据包, 则跳出循环, 留给下次解析, 否则, 说明没有解析到数据, 但是读取了, 所以跳过该次循环进入下次循环
最后判断 if (oldinputlength == in.readablebytes()) , 这里代表out中有数据, 但是并没有从cumulation读数据, 说明这个out的内容是非法的, 直接抛出异常
我们回到channread方法中
我们关注finally中的内容:
finally {
if (cumulation != null && !cumulation.isreadable()) {
numreads = 0;
cumulation.release();
cumulation = null;
} else if (++ numreads >= discardafterreads) {
numreads = 0;
discardsomereadbytes();
}
//记录list长度
int size = out.size();
decodewasnull = !out.insertsincerecycled();
//向下传播
firechannelread(ctx, out, size);
out.recycle();
}首先判断cumulation不为null, 并且没有可读字节, 则将累加器进行释放, 并设置为null
之后记录out的长度, 通过firechannelread(ctx, out, size)将channelread事件进行向下传播, 并回收out对象
我们跟到firechannelread(ctx, out, size)方法中:
static void firechannelread(channelhandlercontext ctx, codecoutputlist msgs, int numelements) {
//遍历list
for (int i = 0; i < numelements; i ++) {
//逐个向下传递
ctx.firechannelread(msgs.getunsafe(i));
}
}这里遍历out集合, 并将里面的元素逐个向下传递
以上就是有关解码的骨架逻辑
看完文章,还可以扫描下面的二维码下载快手极速版领4元红包
除了扫码领红包之外,大家还可以在快手极速版做签到,看视频,做任务,参与抽奖,邀请好友赚钱)。
邀请两个好友奖最高196元,如下图所示: